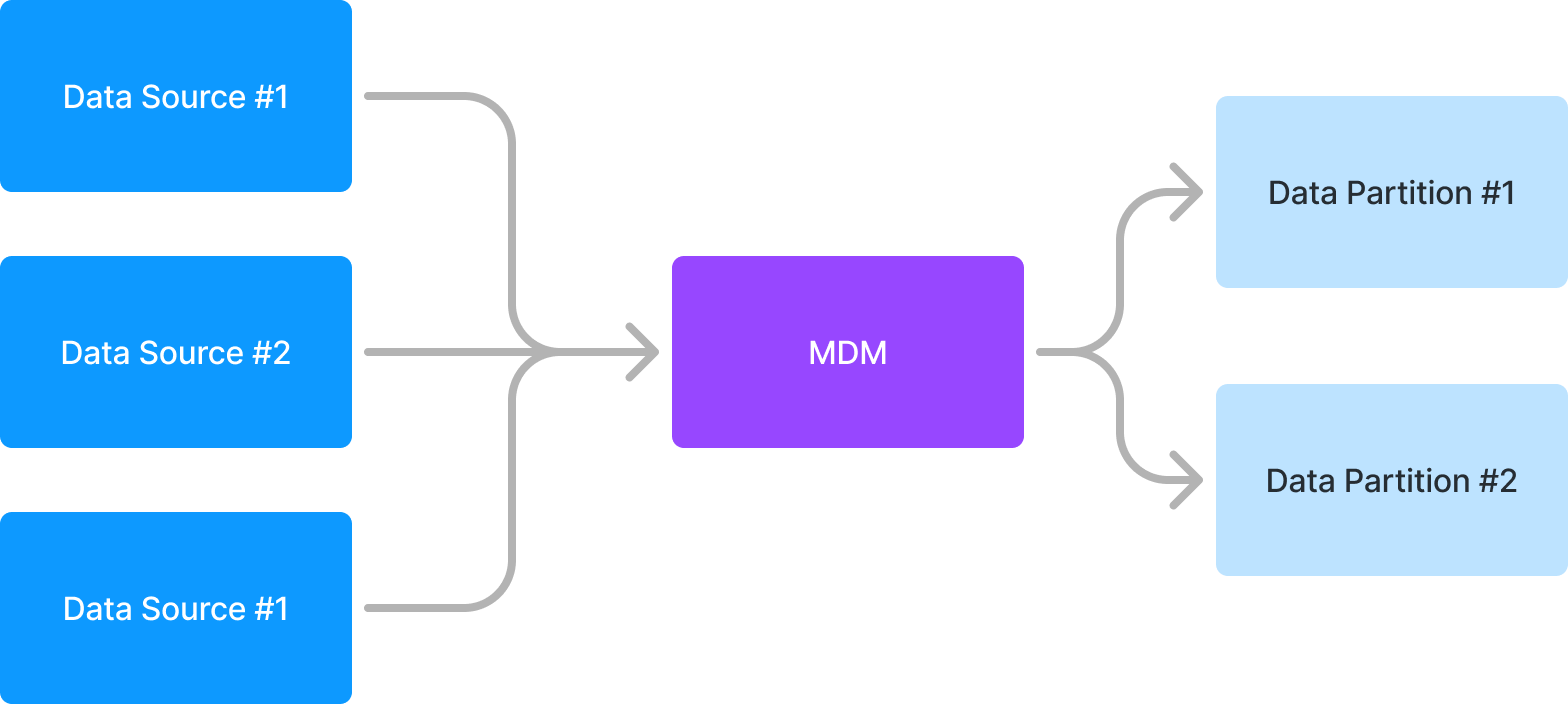
How MDM partitions unify data
- Entity resolution — Records coming from multiple data sources are matched and linked into unified records. The partition surfaces this unified identifier so downstream systems never have to duplicate reconciliation logic.
- Reconciliation rules — Each unified resource or relationship applies reconciliation strategies to decide which properties win, how conflicts are resolved, and when to merge or split entities.
- Search-ready aggregates — After reconciliation, the partition indexes the output so applications can query, facet, and include related information through the Data Partition API.
Configuration model
Partitions are configured through the Data Partition API:source.sources— Declares which source keys contribute records to the MDM collections exposed here.collections— Each entry references an MDM resource key and specifies how to index it. Collections include:propertiesdefining the field schema exposed to downstream queries.mappingsmapping MDM output back to source profiles to enrich unified records.- Optional
reconciliationRulesto select aSYSTEMstrategy or aCLINIA_FUNCTIONthat encapsulates custom merge logic.
relationships— Unified relationships available for traversal. Like collections, they supportmappings,reconciliationRules, andincludeKeydefinitions for each side of the graph.
Collection and relationship connections
Collection and relationship connections define how unified MDM profiles or relationships appear inside a partition. They inherit the identities created by the MDM layer, describe the shape of the records that will be indexed, and map each property back to one or more contributing sources.Collection connections
A collection connection links a partition collection to a unified MDM collection. It covers:- Identity binding — The connection chooses the unified collection whose identifiers the partition will surface.
- Property shape — The
propertiesblock defines the fields and Clinia data types exposed to downstream queries. - Source mappings — Each entry in
mappingsattaches one or more source profiles and points their fields to the unified properties that should receive the values.
propertyMappings use the unified property path as the key (for example address.street) and the source property path as the value. This keeps the transformation declarative and avoids writing ad-hoc merge code.unified-organization profile while reconciling attributes from three different source profiles:
Relationship connections
Relationship connections extend the same concepts to graph edges. They ensure that unified relationship identities flow into the partition, expose thefrom and to sides using the unified profile keys and include paths, and map edge properties back to contributing sources.
Use relationship connections when you want downstream applications to traverse the harmonized graph instead of rebuilding joins on raw source relationships.
Operational considerations
- Latency trade-offs — Unified data becomes available after entity resolution and reconciliation complete. Monitor processing pipelines to understand when refreshed records appear in the partition.
- Governance — Because MDM partitions represent system-of-record entities, manage access through IAM policies and auditing.
- Schema stewardship — MDM profiles evolve independently from source schemas. Coordinate updates with MDM owners to avoid breaking reconciliation logic or downstream consumers.
- Quality feedback — Pair partitions with workflows that push anomalies back to data stewards when reconciliation rules drop attributes or produce conflicting merges.
Traversed Properties
In MDM partitions, traversed properties expand a partition collection beyond the recipient resource. By indexing selected attributes from adjacent relationships and resources, searches can answer cross-entity questions without duplicating data or denormalizing schemas.Traversed properties are a search-only construct. They are indexed with the recipient resource but are not returned by
GET calls to the underlying partition APIs.Configuring traversals
Traversed properties are declared on each collection inside an MDM partition:traversedPropertieslives under the collection entry in the partition configuration.- Each entry references an include configured in the partition (
@practicesabove) and drills into relationship or resource properties using dot notation. - Only primitive and general-purpose complex Clinia data types are supported. Nested properties within custom types can still be reached with dots.
Traversed property notation
@{includeKey}.{propertyKey}— Targets a relationship property, such as@practices.startDate.@{includeKey}.@{resourceType}.{propertyKey}— Targets a property on the adjacent resource, such as@practices.@mdm-facility.address.@{includeKey}.@{resourceType}.{containedKey}.{propertyKey}— Targets a property on a contained resource under the adjacent resource, such as@practices.@mdm-facility.location.address.
Querying traversed properties
When searching a partition collection, use traversed property paths anywhere you would reference a standard property:- Filters — Narrow results to resources where the traversed attribute meets certain criteria.
- Sorting — Order results based on relationship metadata or linked resource attributes.
- Facets and aggregations — Build counts or distributions over traversed values.
Example
Imagine a healthcare directory where providers are linked to facility profiles through aprovider-facility relationship and exposed via the practices include:
- The provider collection stores clinical specialties and licensing information.
- The facility resource holds the location address and accessibility features.
- The relationship captures the employment period and role.
startDate, a single provider search can answer “Which providers accepting new patients work in Montréal right now?” without duplicating address data on every provider record. This approach keeps unified MDM schemas focused while still enabling rich, relationship-aware search experiences.
Related resources
- Create a data partition API reference for the full request payload.
- Browse unified collections to query the harmonized data.
- Entity resolution overview to understand how unified records are generated before they reach the partition.
Keep exploring
Traversed properties overview
Revisit the concepts behind traversed properties and traversal rules.
Traversed filters how-to
Put traversed filters to work in analytic and discovery scenarios.
Entity resolution outcome
Dive into the reconciliation strategies that shape unified records.
Entity resolution preview
Understand how aggregated record previews guide stewarding decisions.